
Hi all! In this first-of-a-series post, I’ll be covering one of the most influential NLP architectures currently used: GPT models! This is an essay version of a talk I gave to Interactive Intelligence at the UW - watch the video here.
When I was learning how Transformers and GPT worked, I found it helpful to develop an intuitive feel for the way the model operates, then dive deeper into the specific implementation. I’ll be following that same approach here.
While these human representations do not perfectly capture the reasons and workings of GPT, these heuristics aid initial understanding. I believe it is a worthwhile trade to make. As one grows more confident in their understanding, they can discard the human abstractions as they please.

GPT takes in a sequence of words and outputs a prediction for the next token. If the prompt is: “The quick brown fox jumps over the lazy”, the output would be: “dog” (assuming it has been trained correctly).
It is essentially a super-version of the autocomplete on your phone:
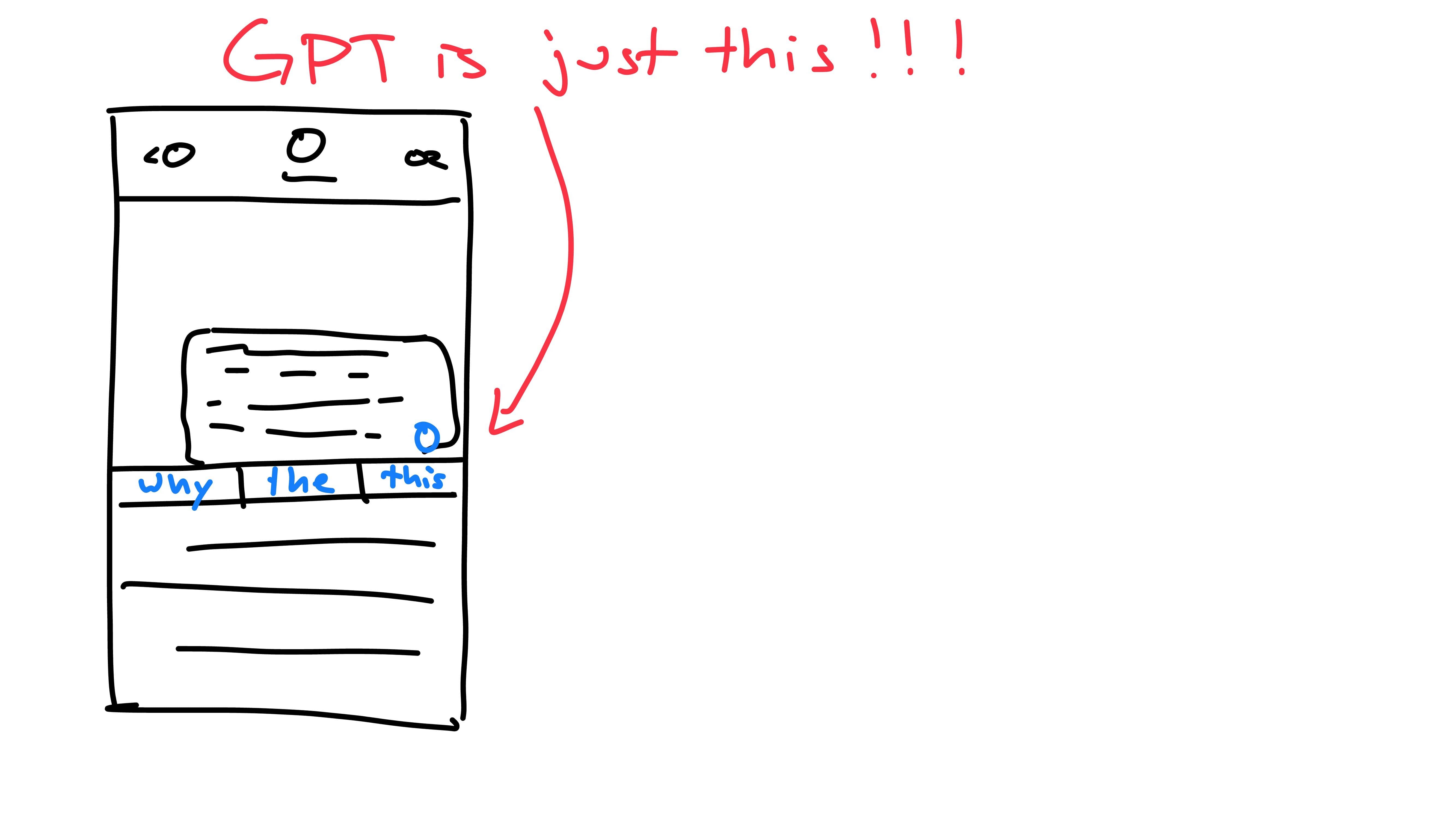
Your phone’s autocomplete will take in an input: the text in the message box, and produce an output: the possible next-word predictions.
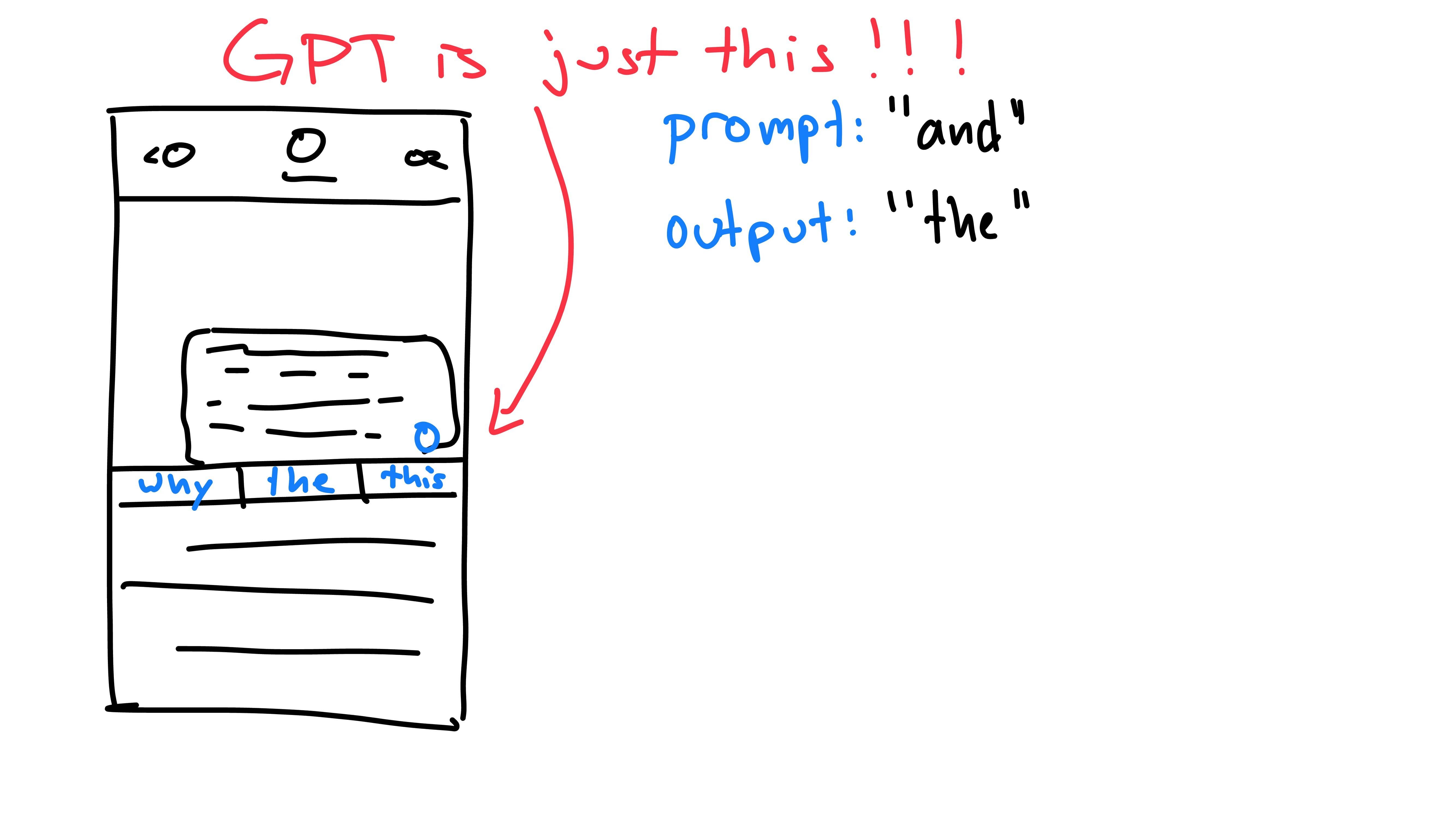
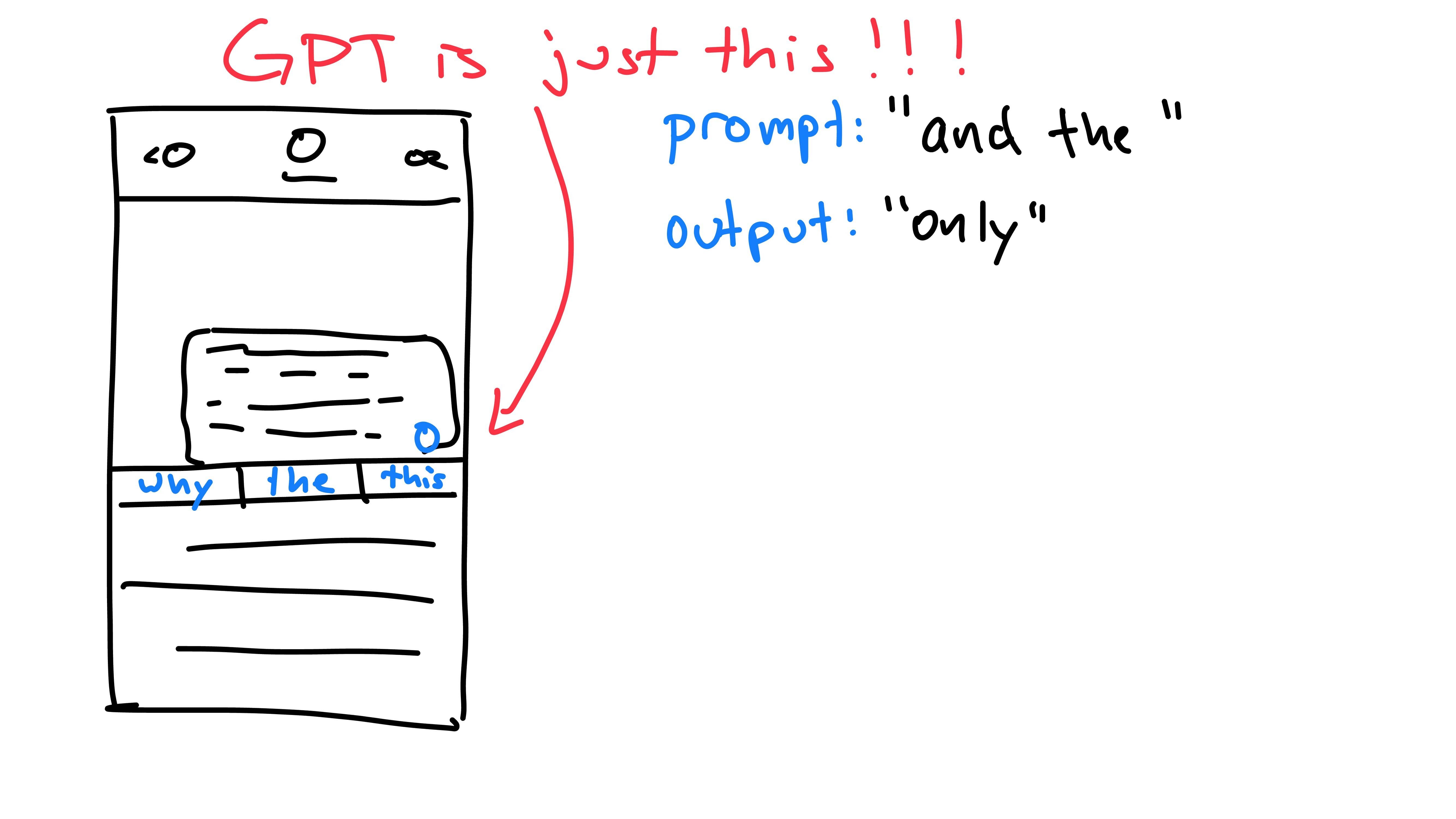
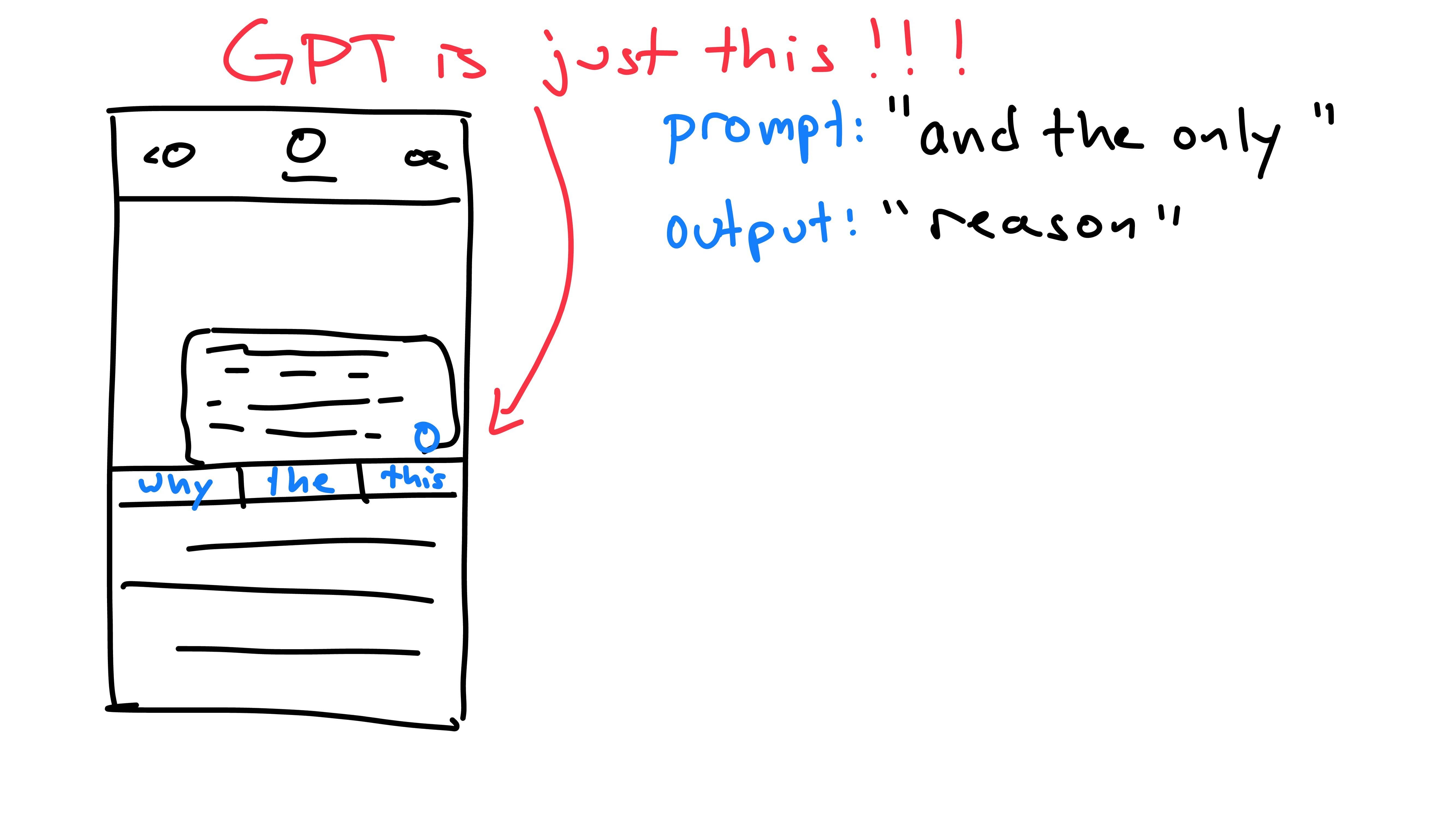
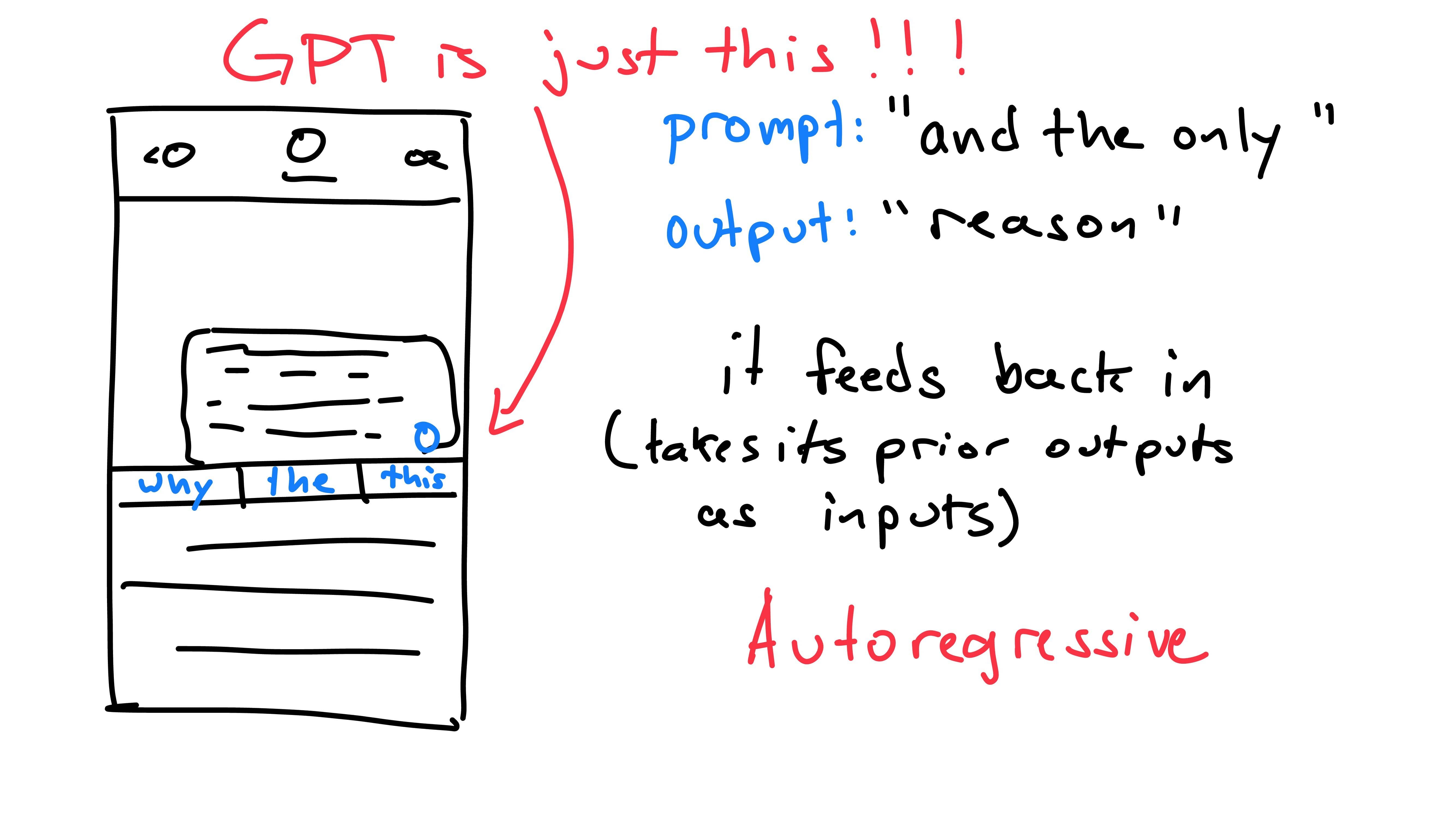
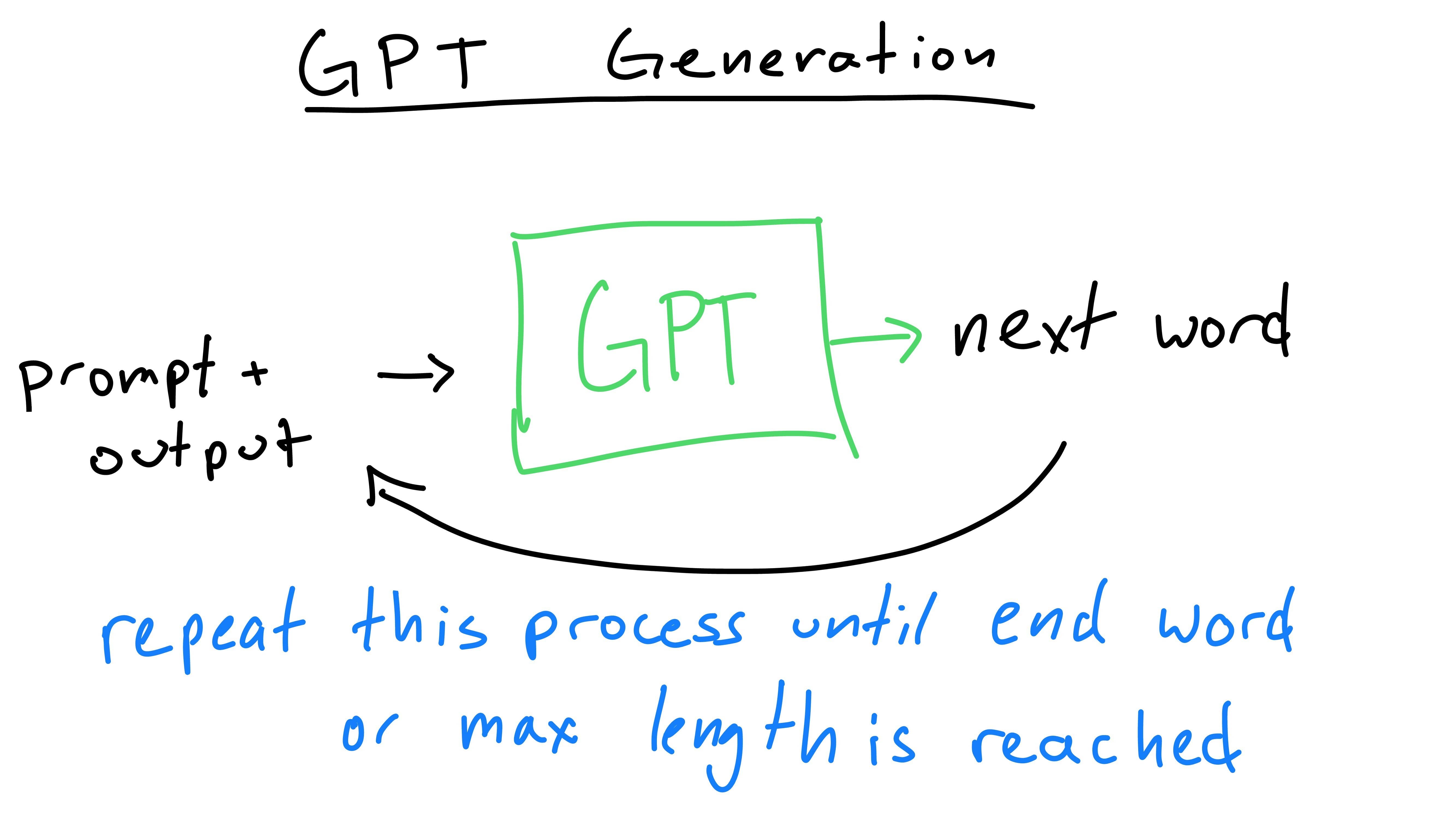
Each time we press the button for a prediction, the phone has viewed the previous words (prompt) and has predicted the next one (output). The next time the button is pressed, we include the previous output as part of the new prompt. This is because the model is autoregressive: it predicts future values based on it’s own past outputs. It does not predict the entire message at once, rather one word at a time, building upon itself. GPT works exactly the same way, predicting the next word, then feeding it back into itself until it has reached a max word limit or stopping character.
Now if you’re like me, you might have tried to write a story or message entirely using autocomplete. If you repeatedly press autocomplete, it will continue to generate words. Here’s an example:
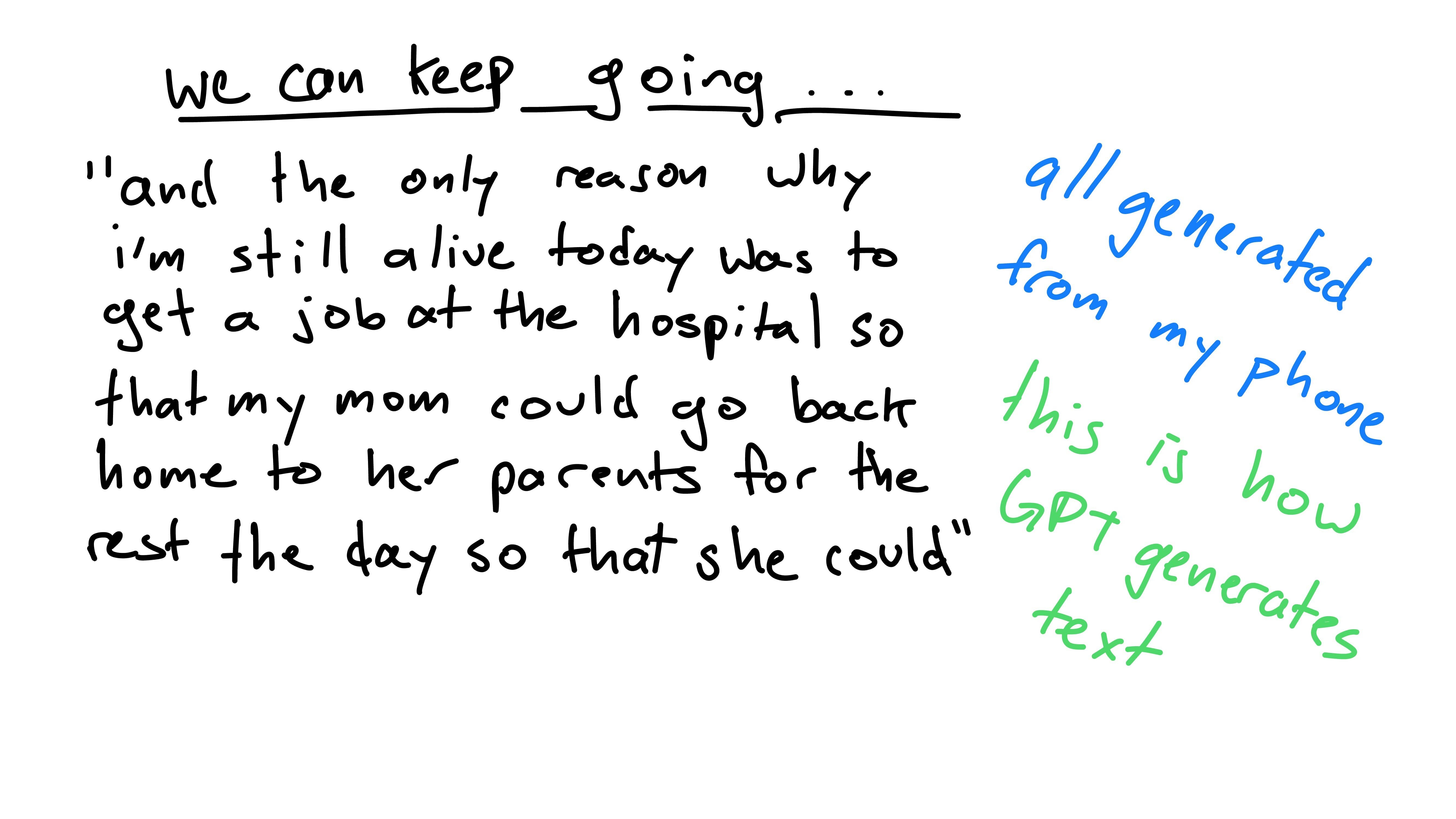
“and the only reason why i’m still alive today was to get a job at the hospital so that my mom could go back home to her parents for the rest the day so that she could”
-Carter’s iPhone
At first glance, this text doesn’t look too off. Small groups of words are in a reasonable order. However, when the entire message is viewed, it makes much less sense. There’s no purpose in this run-on sentence.


Pre-Transformer language models have struggled to capture long term dependencies, similar to as in this message. Now, let’s take a different look at GPT!
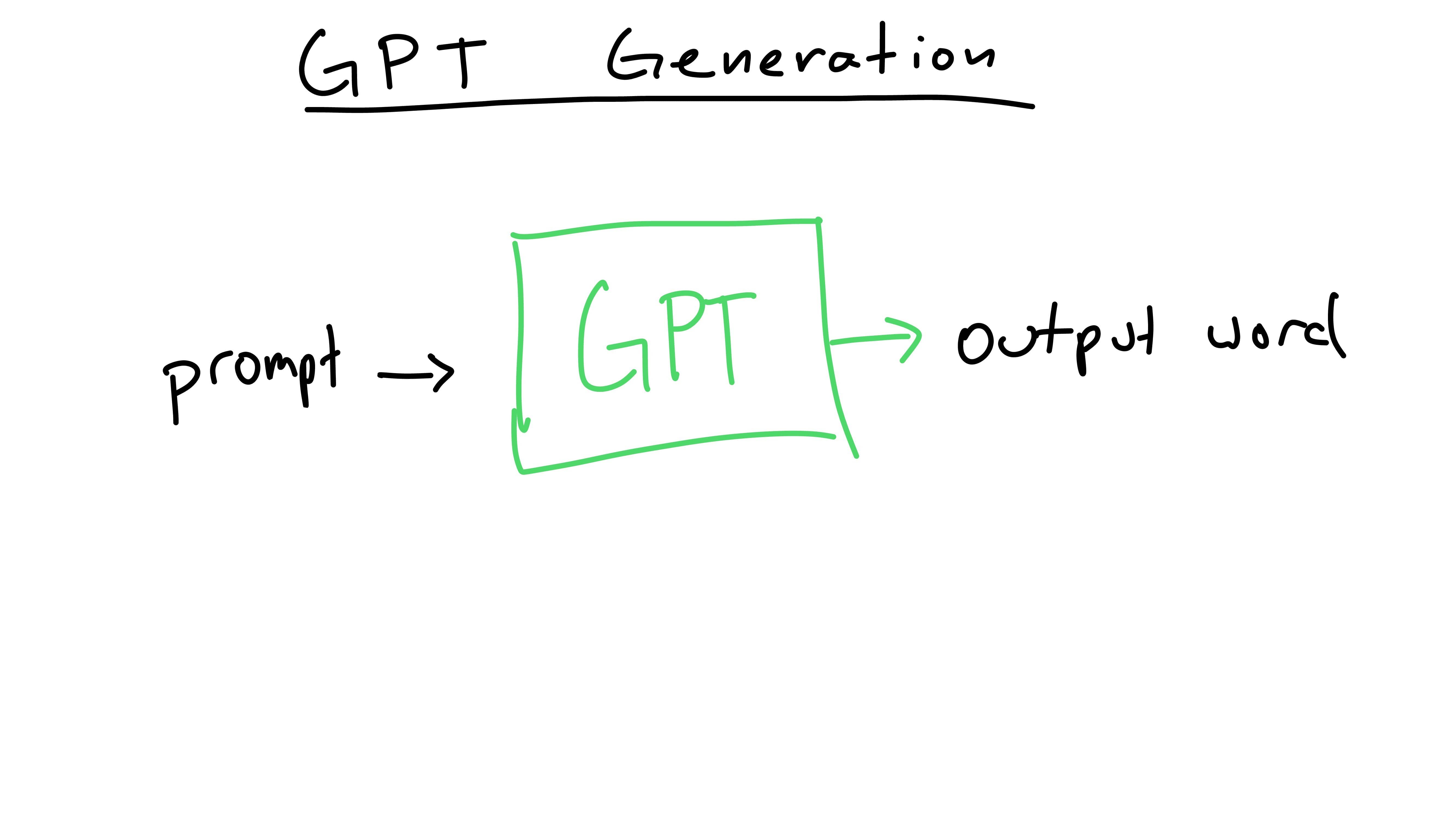
As we’ve discussed before, GPT generates text by taking in an input prompt and outputting a prediction for the next word. As it generates, it will feed previous outputs back to itself, building upon them.
Let’s strip away the very first layer of abstraction. GPT doesn’t quite output a prediction for the next word, but probabilities of which word will be next.
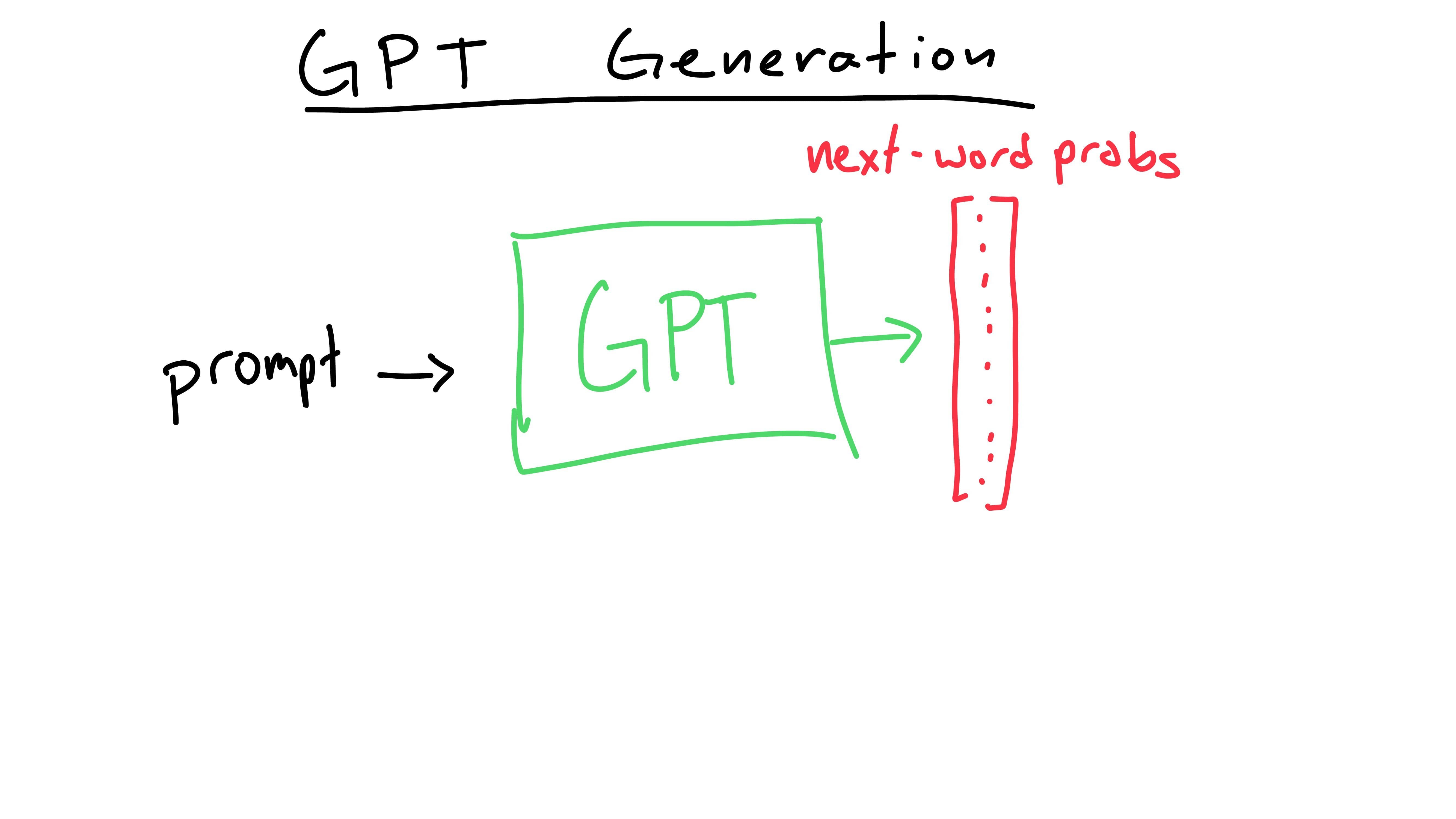
The model assigns every word a probability of being the next word after the prompt. (When you set up the model, you give the model a list of possible words. That’s where each word comes from. More on this later!) Then, you can “decode” these probabilities to get the predicted next word!
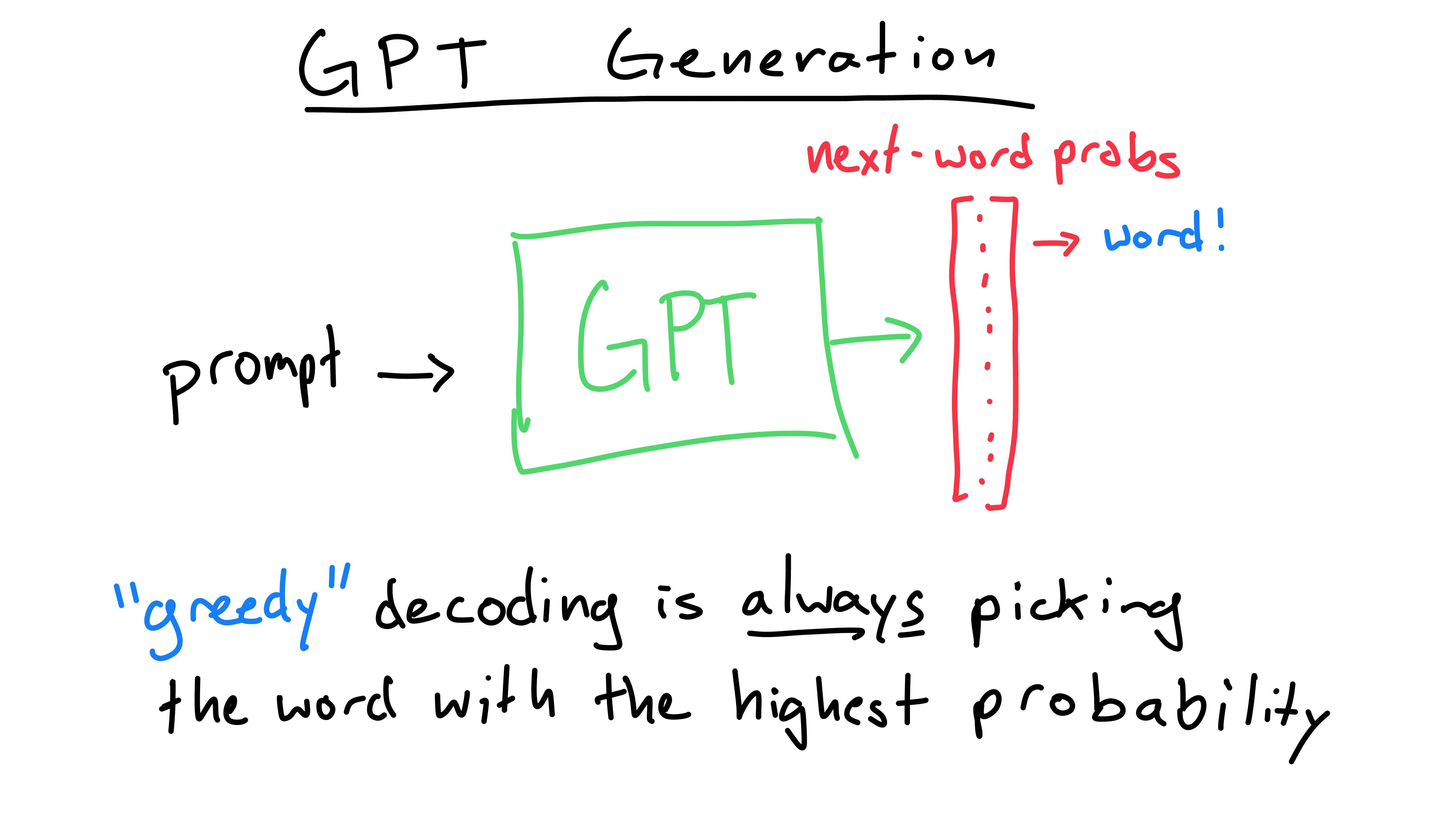
There are multiple ways to decode, but the easiest way is to always pick the word with the highest probability of being next. There are reasons why we wouldn’t just want to pick the most probable word - it might hurt us later.
Here’s a quick example: Whenever we’re walking, the fastest path is typically non-linear. If we always tried to get as “close” to our destination, we might run into a wall. Even if we take the step that reduces the distance the greatest, we might get stuck later. Greedy decoding encounters the same problem.
Computers don’t understand plaintext, they understand numbers. To change passages of text to numbers, we will need to break up English into smaller chunks. These chunks are called “tokens”.

Tokens are small chunks of language that can be used to create a larger phrase. There are multiple ways we could break up a language into smaller tokens. Letters are the smallest pieces of language there are:

If these were the tokens a model was trained on, the model would attempt to predict the next character.
Words are another reasonable choice to use as tokens:

In this case, the model would predict the next word - just like our phones do.
In practice, byte-pair encoding is typically used.

These are building-blocks of English. They can be as small as a single character or as long as a full word. They’re found by compressing a language into smaller chunks (wiki).
In this explanation I’ll use words as example tokens.

Why did we even care about tokens in the first place? Its because we needed to represent English as numbers for the computer. Thus, each token (or word in our example) gets it’s meaning “embedded” into a list of numbers. This is an “embedding vector”.
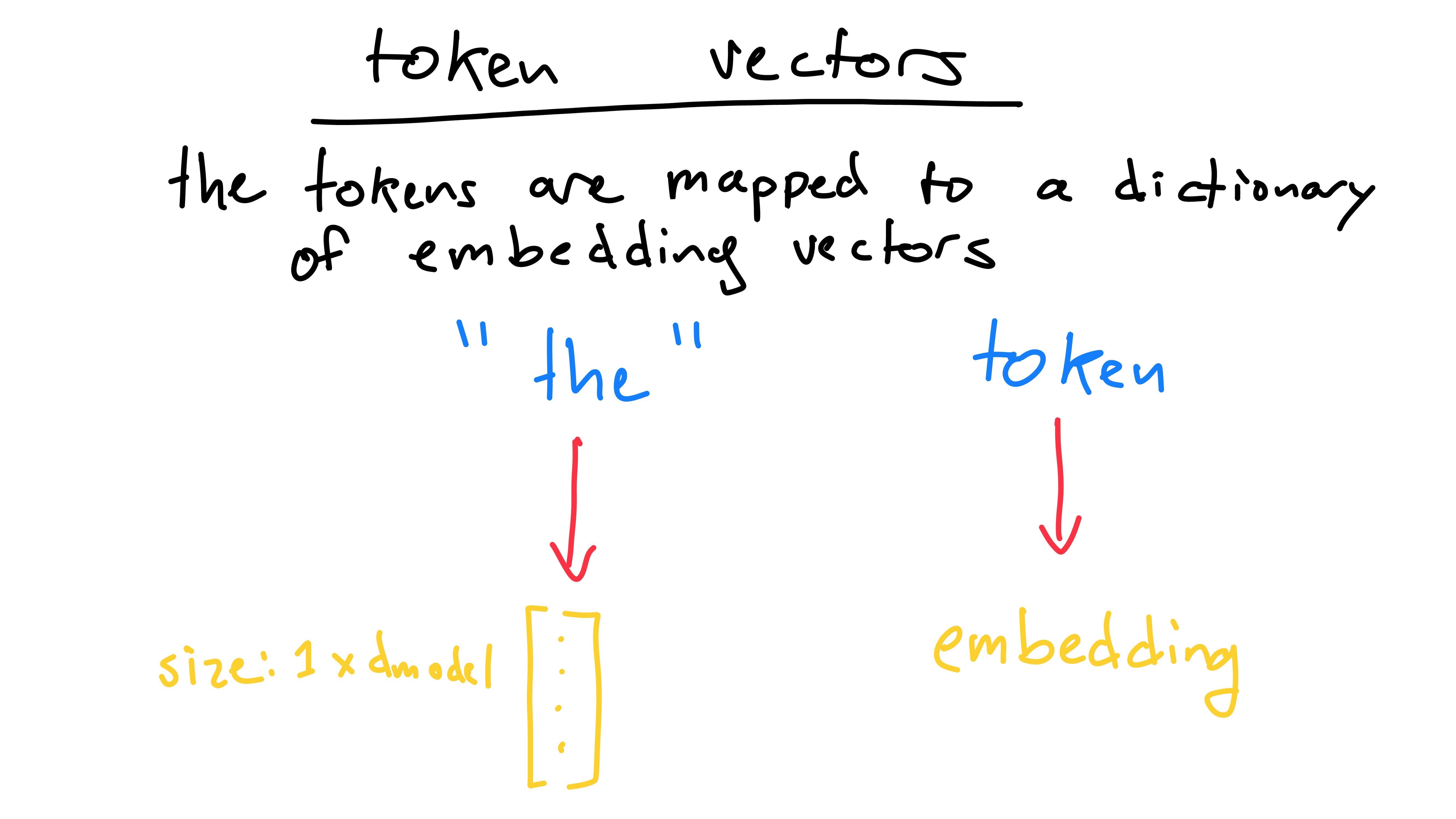
Each token is “encoded” to an embedding vector. For example, the word
“the” is encoded to a vector of numbers representing the meaning of the
word (I’ll get to what the “meaning of a word” represents in a moment).
The length of this vector is dmodel - the dimensionality of
the model, a hyperparameter that we define.
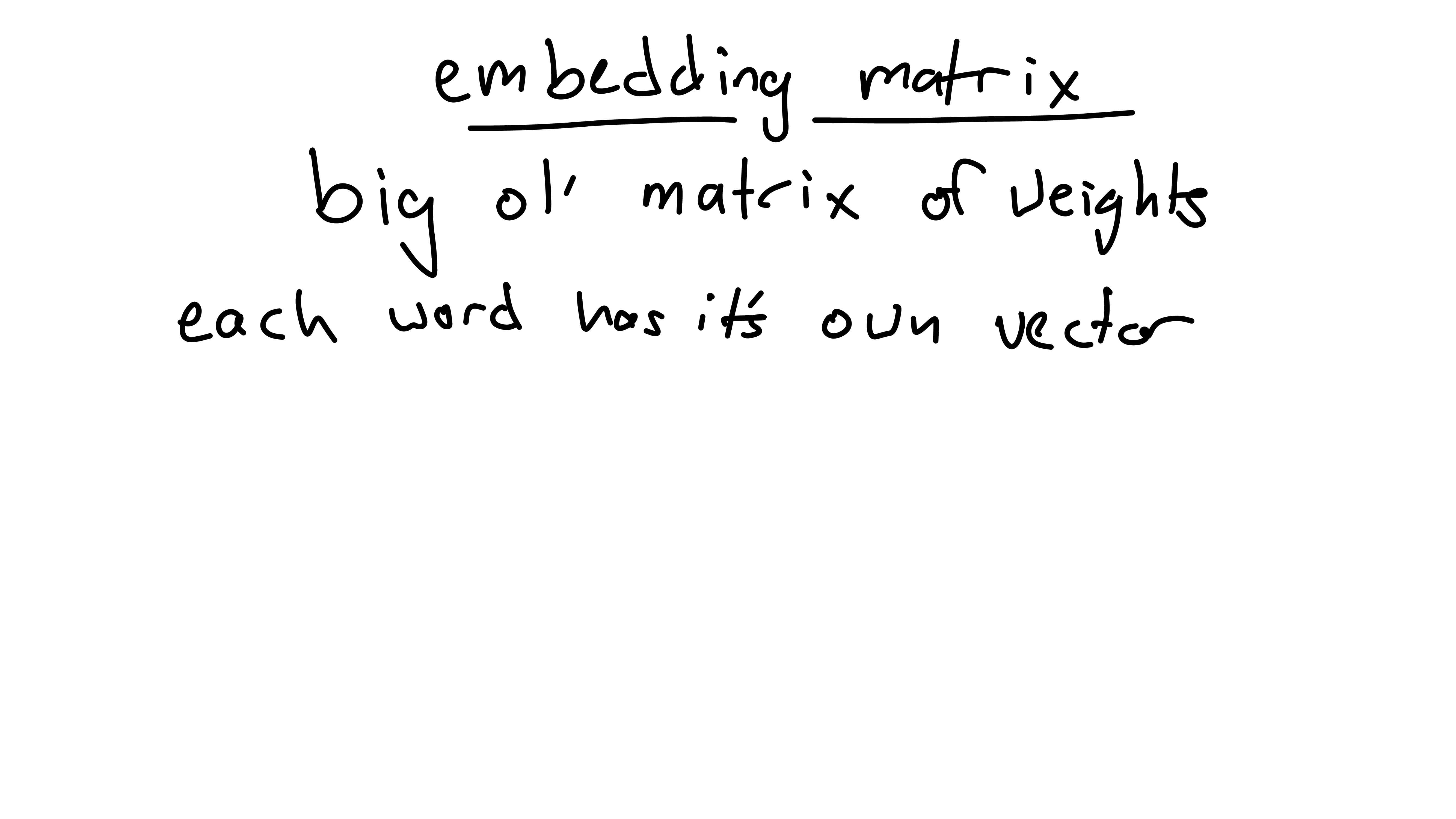
Where do these weights come from? They’re rows in a large embedding
matrix, of shape (vocab_size, dmodel).
vocab_size is the number of tokens (in our case, the number
of English words).

Now, where does this embedding matrix come from? Typically, there are two options. First, it could be learned while training the overall model. Second, and often more practically, we use “pre-trained” weights. These are just weights that have been already learned by others.
- carter